

This post was originally published on Pete's blog, PeteSearch. Subscribe to PeteSearch and follow Pete on Twitter to stay current with Pete's thoughts and ideas.

Common Crawl is one of those projects where I rant and rave about how world-changing it will be, and often all I get in response is a quizzical look. It's an actively-updated and programmatically-accessible archive of public web pages, with over five billion crawled so far. So what, you say? This is going to be the foundation of a whole family of applications that have never been possible outside of the largest corporations. It's mega-scale web-crawling for the masses, and will enable startups and hackers to innovate around ideas like a dictionary built from the web, reverse-engineering postal codes, or any other application that can benefit from huge amounts of real-world content. Rather than grabbing each of you by the lapels individually and ranting, I thought it would be more productive to give you a simple example of how you can run your own code across the archived pages. It's currently released as an Amazon Public Data Set, which means you don't pay for access from Amazon servers, so I'll show you how on their Elastic MapReduce service.
I'm grateful to Ben Nagy for the original Ruby code I'm basing this on. I've made minimal changes to his original code, and built a step-by-step guide describing exactly how to run it. If you're interested in the Java equivalent, I recommend this alternative five-minute guide.
1 - Fetch the example code from GitHub
You'll need git to get the example source code. If you don't already have it, there's a good guide to installing it here:
http://help.github.com/mac-set-up-git/From a terminal prompt, you'll need to run the following command to pull it from my github project:
2 - Add your Amazon keys
If you don't already have an Amazon account, go to this page and sign up:
https://aws-portal.amazon.com/gp/aws/developer/registration/index.html
Your keys should be accessible here:
https://aws-portal.amazon.com/gp/aws/securityCredentials
To access the data set, you need to supply the public and secret keys. Open upextension_map.rb in your editor and just below the CHANGEME comment add your own keys (it's currently around line 61).
3 - Sign in to the EC2 web console
To control the Amazon web services you'll need to run the code, you need to be signed in on this page: http://console.aws.amazon.com
4 - Create four buckets on S3

Buckets are a bit like top-level folders in Amazon's S3 storage system. They need to have globally-unique names which don't clash with any other Amazon user's buckets, so when you see me using com.petewarden as a prefix, replace that with something else unique, like your own domain name. Click on the S3 tab at the top of the page and then click the Create Bucket button at the top of the left pane, and enter com.petewarden.commoncrawl01input for the first bucket. Repeat with the following three other buckets:com.petewarden.commoncrawl01outputcom.petewarden.commoncrawl01scriptscom.petewarden.commoncrawl01logging
The last part of their names is meant to indicate what they'll be used for. 'scripts' will hold the source code for your job, 'input' the files that are fed into the code, 'output' will hold the results of the job, and 'logging' will have any error messages it generates.
5 - Upload files to your buckets

Select your 'scripts' bucket in the left-hand pane, and click the Upload button in the center pane. Select extension_map.rb, extension_reduce.rb, and setup.sh from the folder on your local machine where you cloned the git project. Click Start Upload, and it should only take a few seconds. Do the same steps for the 'input' bucket and the example_input.txt file.
6 - Create the Elastic MapReduce job
The EMR service actually creates a Hadoop cluster for you and runs your code on it, but the details are mostly hidden behind their user interface. Click on the Elastic MapReduce tab at the top, and then the Create New Job Flow button to get started.
7 - Describe the job

The Job Flow Name is only used for display purposes, so I normally put something that will remind me of what I'm doing, with an informal version number at the end. Leave the Create a Job Flow radio button on Run your own application, but choose Streaming from the drop-down menu.
8 - Tell it where your code and data are
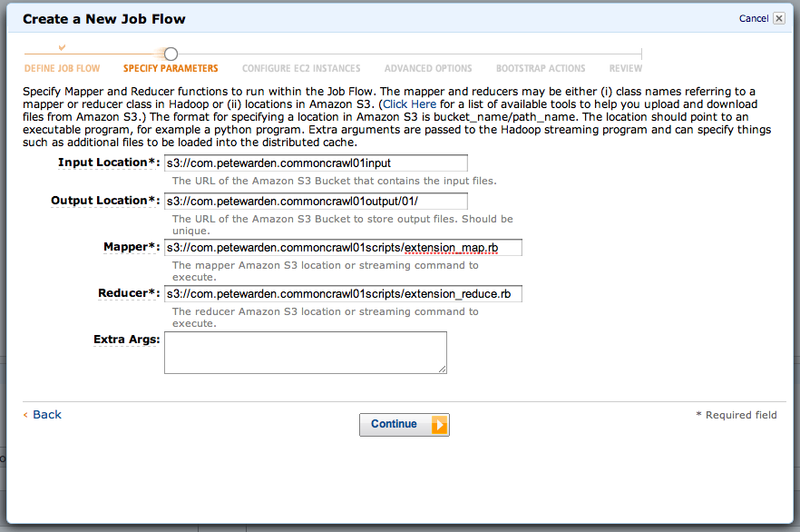
This is probably the trickiest stage of the job setup. You need to put in the S3 URL (the bucket name prefixed with s3://) for the inputs and outputs of your job. Input Location should be the root folder of the bucket where you put the example_input.txt file, in my case 's3://com.petewarden.commoncrawl01input'. Note that this one is a folder, not a single file, and it will read whichever files are in that bucket below that location.
The Output Location is also going to be a folder, but the job itself will create it, so it mustn't already exist (you'll get an error if it does). This even applies to the root folder on the bucket, so you must have a non-existent folder suffix. In this example I'm using 's3://com.petewarden.commoncrawl01output/01/'.
The Mapper and Reducer fields should point at the source code files you uploaded to your 'scripts' bucket, 's3://com.petewarden.commoncrawl01scripts/extension_map.rb' and 's3://com.petewarden.commoncrawl01scripts/extension_map.rb'. You can leave the Extra Args field blank, and click Continue.
9 - Choose how many machines you'll run on

The defaults on this screen should be fine, with m1.small instance types everywhere, two instances in the core group, and zero in the task group. Once you get more advanced, you can experiment with different types and larger numbers, but I've kept the inputs to this example very small, so it should only take twenty minutes on the default three-machine cluster, which will cost you less than 30 cents. Click Continue.
10 - Set up logging

Hadoop can be a hard beast to debug, so I always ask Elastic MapReduce to write out copies of the log files to a bucket so I can use them to figure out what went wrong. On this screen, leave everything else at the defaults but put the location of your 'logging' bucket for the Amazon S3 Log Path, in this case 's3://com.petewarden.commoncrawl01logging'. A new folder with a unique name will be created for every job you run, so you can specify the root of your bucket. Click Continue.
11 - Specify a boot script

The default virtual machine images Amazon supplies are a bit old, so we need to run a script when we start each machine to install missing software. We do this by selecting the Configure your Bootstrap Actions button, choosing Custom Action for the Action Type, and then putting in the location of the setup.sh file we uploaded, e.g 's3://com.petewarden.commoncrawl01scripts/setup.sh'. After you've done that, click Continue.
12 - Run your job

The last screen shows the settings you chose, so take a quick look to spot any typos, and then click Create Job Flow. The main screen should now contain a new job, with the status 'Starting' next to it. After a couple of minutes, that should change to 'Bootstrapping', which takes around ten minutes, and then running the job, which only takes two or three.
Debugging all the possible errors is beyond the scope of this post, but a good start is poking around the contents of the logging bucket, and looking at any description the web UI gives you.

Once the job has successfully run, you should see a few files beginning 'part-' inside the folder you specified on the output bucket. If you open one of these up, you'll see the results of the job.

This job is just a 'Hello World' program for walking the Common Crawl data set in Ruby, and simply counts the frequency of mime types and URL suffixes, and I've only pointed it at a small subset of the data. What's important is that this gives you a starting point to write your own Ruby algorithms to analyse the wealth of information that's buried in this archive. Take a look at the last few lines of extension_map.rb to see where you can add your own code, and edit example_input.txt to add more of the data set once you're ready to sink your teeth in. Big thanks again to Ben Nagy for putting the code together, and if you're interested in understanding Hadoop and Elastic MapReduce in more detail, I created a video training session that might be helpful.
I can't wait to see all the applications that come out of the Common Crawl data set, so get coding!

.svg)
