

Introduction
Common Crawl is a part of AWS Open Data Sponsorship program, and our data is available freely in a S3 bucket named “commoncrawl”. Our datasets have become very popular over time, with downloads doubling every 6 months for several years in a row.
We (and our users) are now experiencing frequent and severe performance issues. Many users, even those sending a single request, are seeing “503 slow down” errors. The main cause is a small number of organizations who are sending extremely large numbers of requests – sometimes millions per second, more than 100X as many requests as we could possibly serve. These organizations are also not backing off properly after seeing failures. These download strategies can end up becoming a DDoS (distributed denial of service attack) against our S3 bucket.
We have been working with Amazon’s S3 and network teams to resolve this issue. Together, we have made several configuration changes that have improved performance. We have also experimented with some of Amazon’s WAF tools, without much success. Another fix would be to contact the organizations to work with them to send an acceptable number of requests.
However, our logs do not always indicate who is attempting the downloads. This makes it challenging to contact users and ask them to be more reasonable with request rates and retries.
Status Website
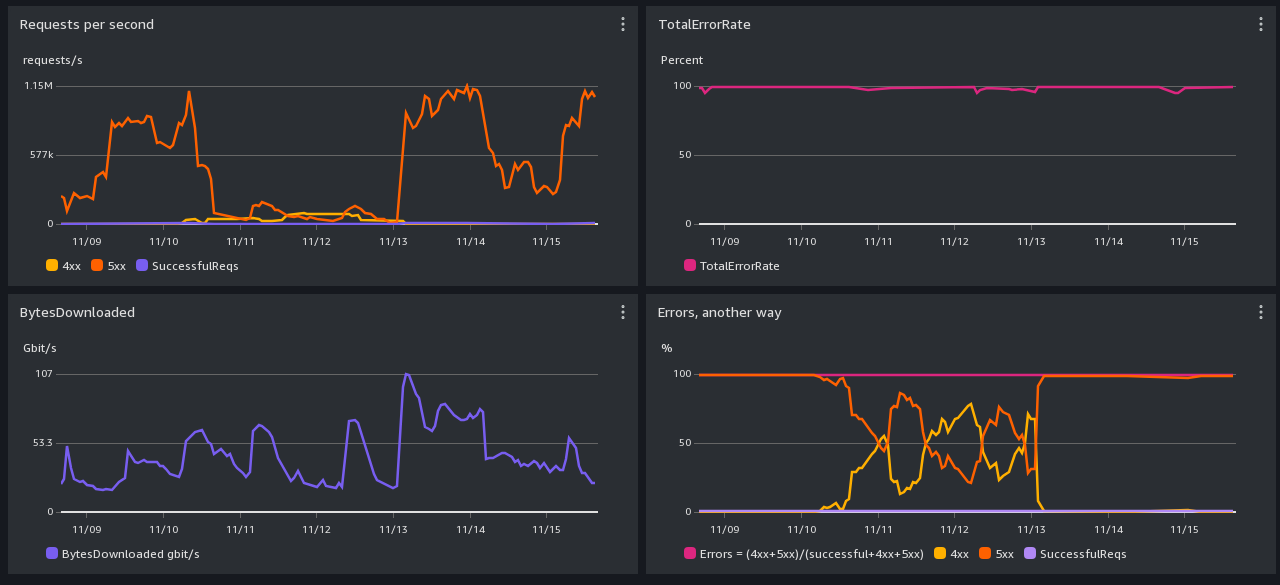
To help us and our users understand the ups and downs in our performance, we have created a new status website, https://status.commoncrawl.org/. It has performance graphs for the two ways of accessing our data (https and S3), and there are graphs for the previous week, day, and month.
These graphs are a bit hard to understand, so here are some additional details:
- Requests to https are being filtered by Amazon CloudFront first, and if they pass that filter, they are then sent to S3 and also appear in the S3 graphs.
- There is no way to see separate request counts and error rates for small vs. large requests.
- Our bucket can handle thousands of requests per second; when it sees 10s of thousands of requests per second it becomes unhappy and runs at reduced capacity for a while.
- When millions of requests per second arrive, performance slows.
- When you see bandwidths in the 200-500 gigabits per second range, that’s 25-to-60 1 gigabyte files being downloaded per second.
Here are example status graphs from November 09-16, 2023:

Practical Advice for Rate-limits and Retrying Politely
Starting in October, extremely aggressive downloaders have been causing high traffic to our AWS-hosted open data bucket. The main symptom users will see are "503 Slow Down" errors when accessing our bucket. Once the bucket is temporarily overwhelmed, it sends these 503 errors to everyone, including users sending even a single request.
What’s a reasonable number of requests per second to send?
If you’re downloading in bulk, you can see from our graphs that we tend to sustain 100-500 gigabits per second for everyone combined, so you’ll want to be a fraction of that bandwidth. Retrying once per second after you receive a 503 is polite enough.
If you’re sending small requests for index information or single webpages contained in WARC files, we can handle a few thousand requests per second total for everyone combined, so you’ll want to stay below 10 per second, or if things someday become better, perhaps 100 per second. Whenever you get a 503 error, you should not retry in less than a second, and you should back off to at least 10 seconds per retry.
Using commoncrawl over HTTPS
For bulk downloads, such as whole files, it's possible to work around these 503s by politely retrying many times. Retrying no more than once per second is polite enough. And once you are lucky and get a request through, you'll get the entire file without any further rate limit checks.
Here are some recipes for enabling retries for popular command-line tools:
curl with 1 second retries, and download filename taken from URL:
wget with 1 second retries:
This retry technique does not work well enough for partial file downloads, such as index lookups and downloading individual webpage captures from within a WARC file.
Using commoncrawl via an S3 client
As you can see in the various graphs, direct S3 usage is working better than usage via CloudFront (https). However, most S3 clients tend to split large downloads into many separate requests, and this makes them more vulnerable to being killed by 503s. We do not yet have advice for configuring an S3 client to avoid this large-file download problem.
There is an alternative for S3 API users which costs money – ordinarily copying commoncrawl data is free – which we will write up in the near future.
Using Amazon Athena
Amazon Athena makes many small requests over S3 as it does its work. Unfortunately, it does not try very hard to retry 503 problems, and we have been unable to figure out a configuration for Athena that improves its retries. If you simply run a failed transaction a second time, you'll get billed again and it probably also won't succeed.
We use Amazon Athena queries ourselves as part of our crawling configuration. Because we make a lot of queries, we downloaded the parquet columnar index files for the past few crawls and used DuckDB to run SQL queries against them.
In Python, starting DuckDB and running a query looks like this:
Contact Us for Help
If you would like us to review how you’re downloading our data, please use the contact form on our website to send us a message. We’d love to hear from you!

.svg)
